A Data Explorer for Anti-Money Laundering Compliance Teams
Powerful Search Queries Without the Complicated Syntax

Product Design

Information Architecture

I was asked to redesign Beam's Data Explorer feature with the goal of making it easier and more predictable to use.
Before I could begin to answer the question about how to improve this feature, I first needed to understand the existing solution on the most fundamental level. Who is it for, and what problem does it aim to solve?
When I first asked the team of engineers that originally designed this feature what its purpose was, I got a somewhat vague answer: "The Data Explorer helps users find data". Of course, this triggered the typical designer follow-up question: "But why?"
I didn't have the luxury of interviewing real users at this stage of the project, but through a series of focused brainstorm sessions with the engineering team, my PM, and the founders, we were able to contextualize this feature within a real-world scenario. This was based on the group's collective knowledge and experience working in and with compliance teams.
The result of this meeting was a problem definition. To be fair it was just a hypothesis, but it was at least a start, something we could hold on to as we moved forward in the discovery process.
Compliance teams who rely on their company’s data team fail to be responsive to regulators' requests.
The back-and-forth game of telephone between auditors, compliance teams, and data teams can take a lot of time, building frustration eroding confidence.
During the course of an audit of a compliance team, the auditor will ask the team for various data sets, with the aim of answering questions that go beyond known investigations.
For example: "How many transactions over $6000 have you seen coming out of country x in the past quarter".
Traditionally, compliance teams would need to engage with an in house data team to provide these deliverables. This can take time, especially if there are follow-up questions from the auditor.

Beam already had a tool that attempted to solve this problem (as defined in the previous section). I did an audit to understand where it was falling short of its goal.
The first thing I learned was that the tool was basically an Elasticsearch query input with a big list of fields underneath it that served as a key.
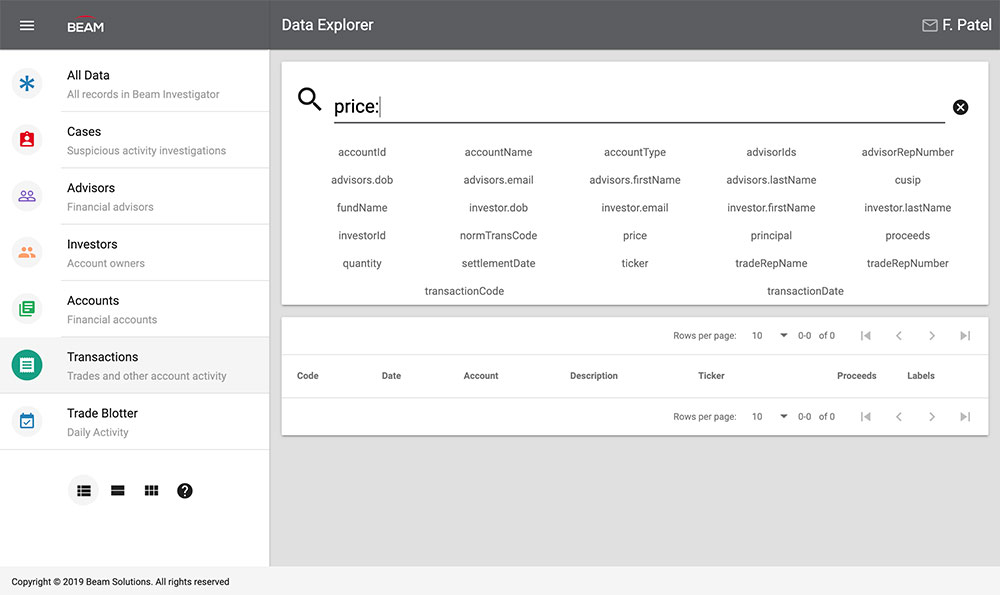
The tool requires the user to know Elastic syntax
Even though there is a handy key that lists out all the possible fields you can filter by, there's no way of knowing what type of field it is and how best to filter it. Is it a number? A string? A date range? You'd have to know the entire data model by heart to really make use of this.
The field key takes up a lot of vertical space.
The table below the query input is empty by default. You have to run a query before you see anything, but what if you don't know exactly what you're looking for yet? It's a daunting place to start.
At this point, I had a vague idea about what an improved experience might look like, but I also had some questions. I spoke to a handful of compliance professionals to get their perspective.
Here are some of the findings:

“We want to empower compliance teams to quickly find and deliver complex data sets that cover a wide range of needs driven by audits and recurring compliance reports. How might we build a data filtering tool that is robust, yet can be universally understood without prerequisite familiarity with a specific database language?”
This reminded me of one of my favorite Venn diagrams related to designing software for professionals.

In other words, we want to have our cake and eat it too.
I went through several rapid iterations of wire-flows that I showed to users and stakeholders along the way for quick gut checks and course corrections.
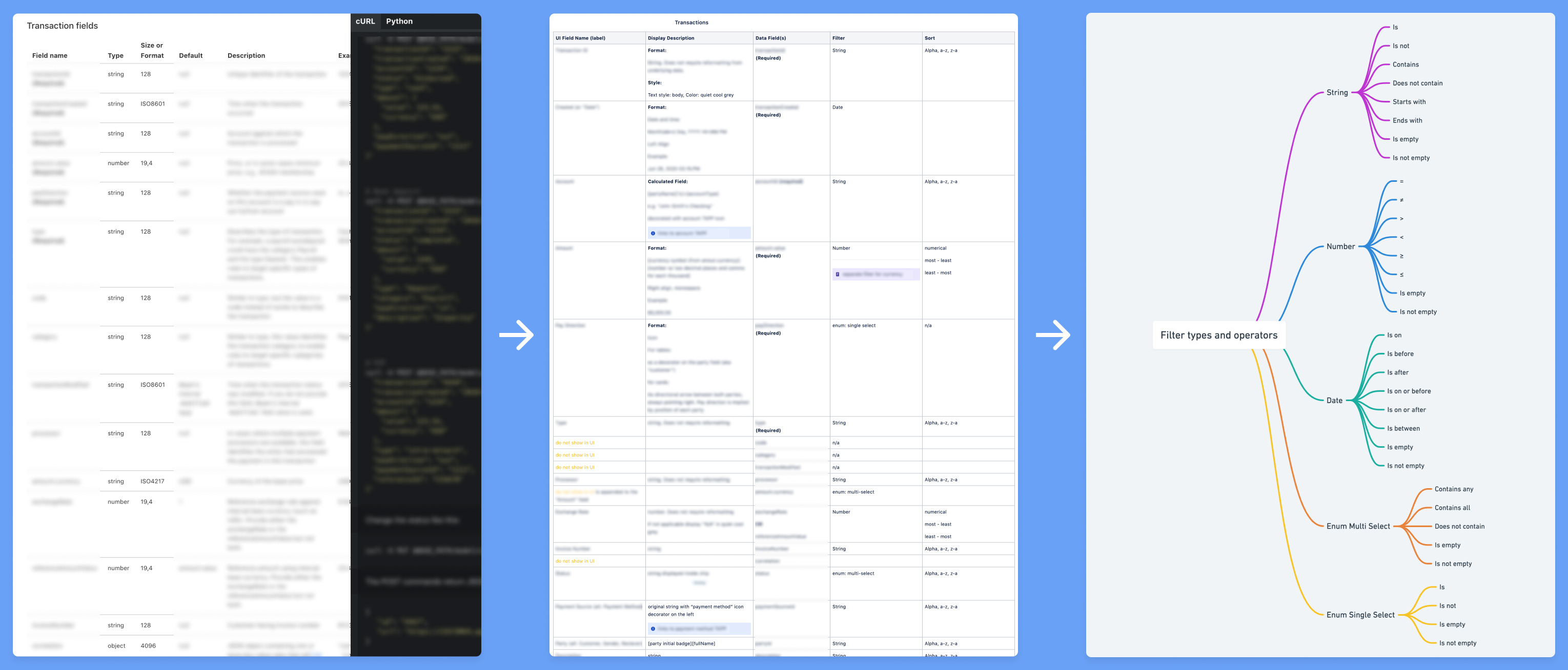
To understand what kind of filters the query builder would need and how the user would interact with them, I needed to first understand Beam's data model. Our wonderful technical writer provided me with all the materials I needed to deep dive into all the data types and fields users would typically be looking at. While the API documentation I was given was undoubtedly great for an engineer, I needed to re-document it in a way that would help me look at it from a user's perspective, so I created a big table in Confluence that helped me do just that.
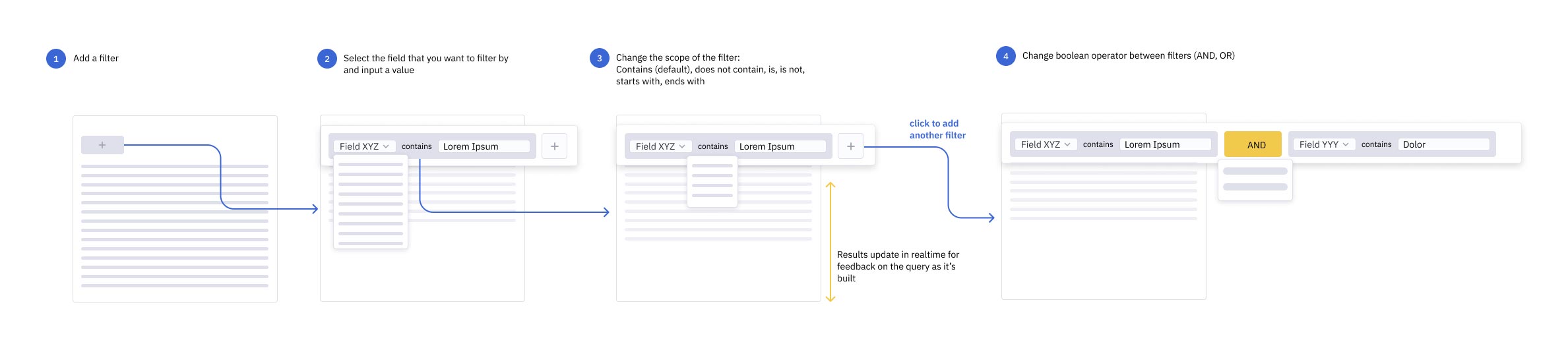
Next, I was able to boil down the kinds of filters we'd need to design to support all of this data. I put together a mind map to help keep track of all the filter types and the appropriate operators for each.
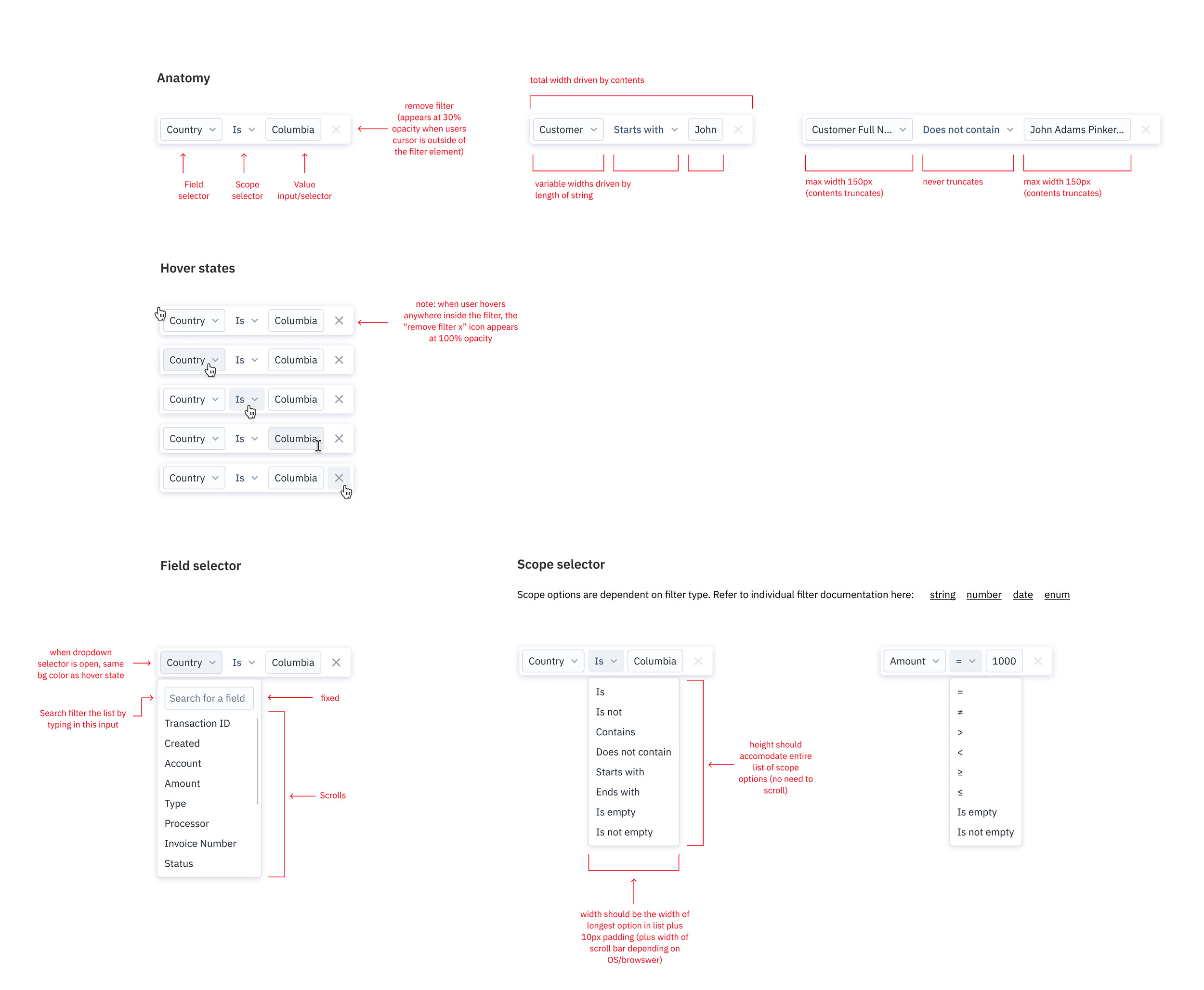
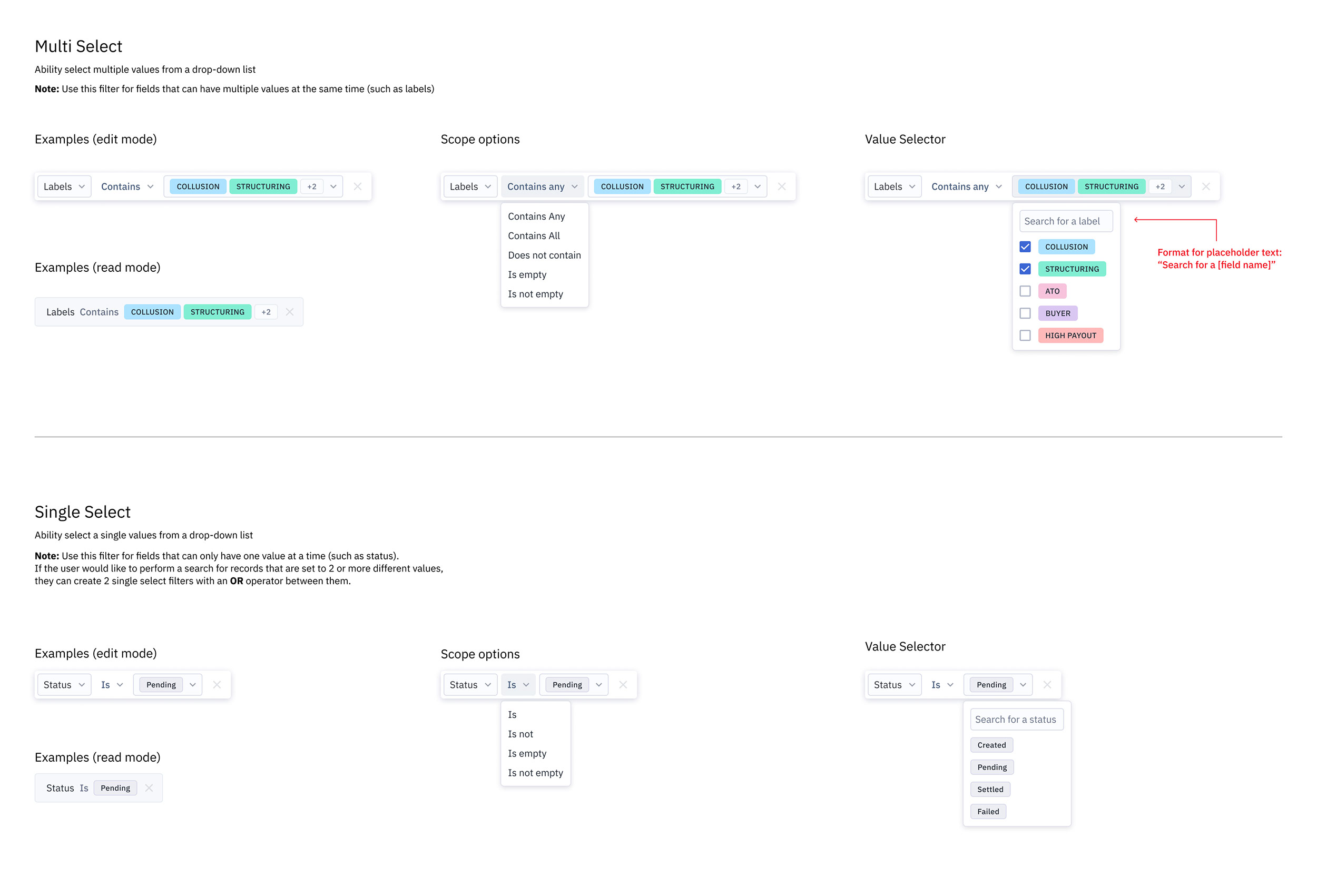
With all the painstaking documentation groundwork done, I was able to focus on designing a common pattern for all filters in the data explorer, along with specific designs for each permutation depending on the filter type.
Below is an example of the kind of detailed design spec I believe is crucial not only for smooth developer handoff but also for thinking through every possible micro-scenario as a designer.
I used Figma to create several prototypes based on some specific auditing scenarios. I used these prototypes to validate the usability of the design. First internally, then after some feedback and iterations, I tested it with external users.
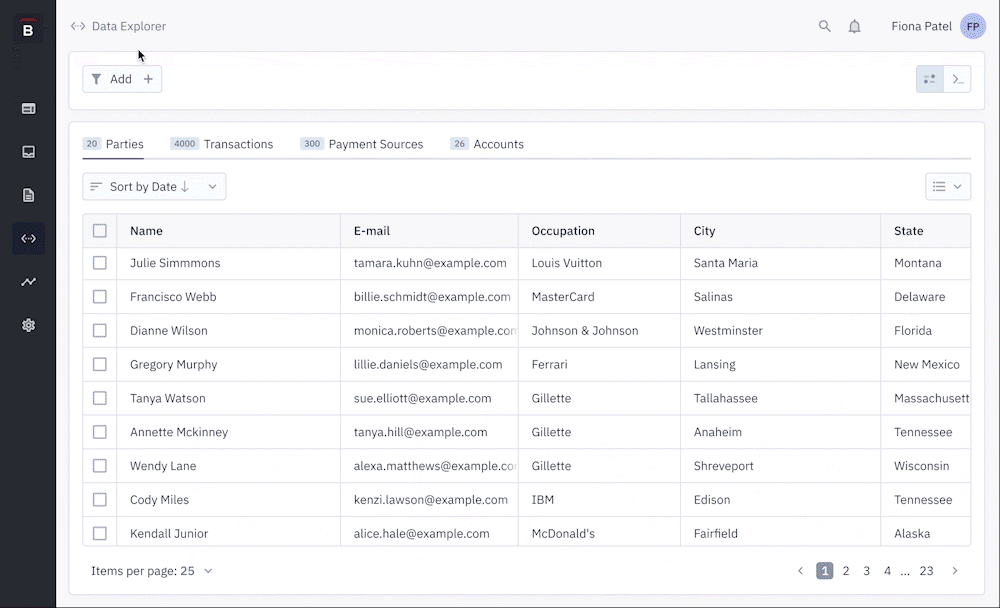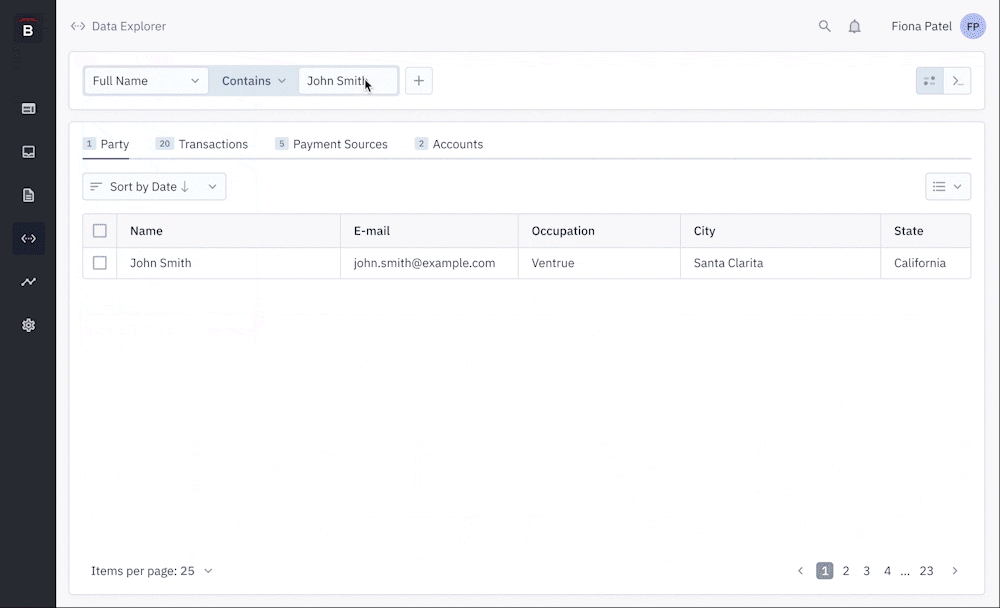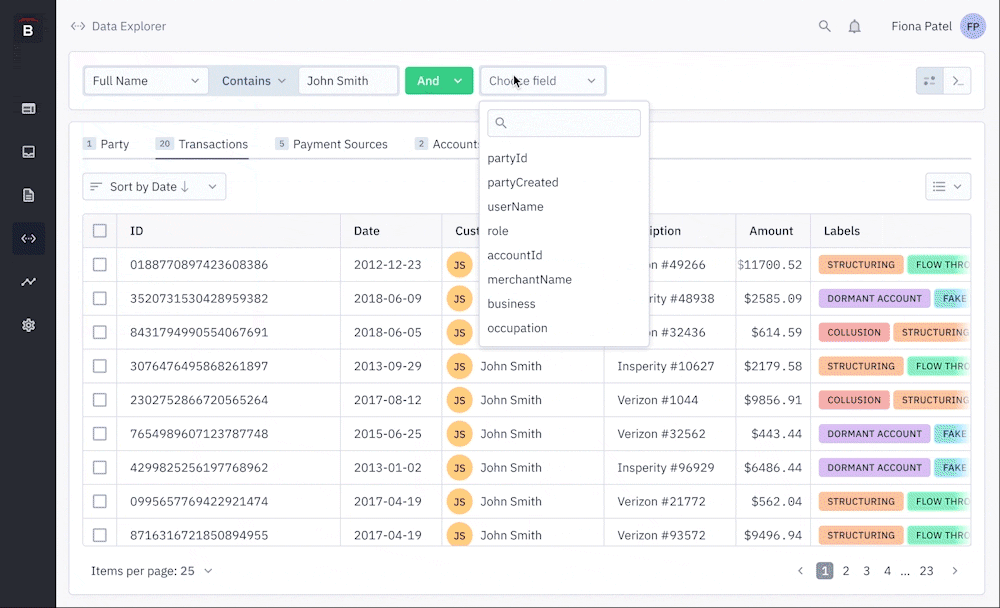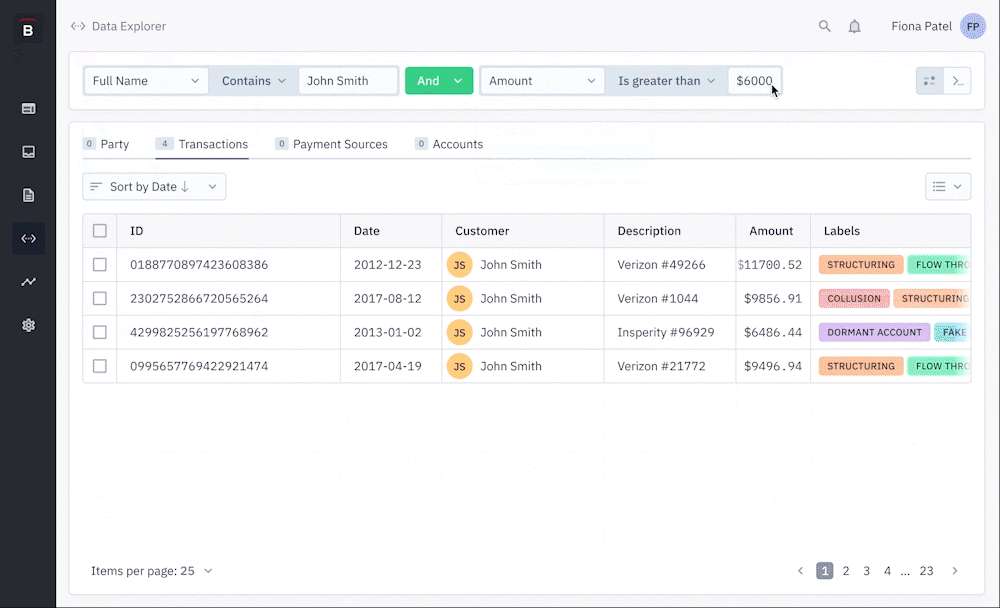
When doing usability testing, I create a prototype for each pre-defined user goal and organize the outcome from that test into 3 main categories:
We learned that users liked the ability to create queries for all data types simultaneously, seeing the results update in real-time across all the tabs. However, the data types don't all share the same fields, so the query logic would break in some instances. We needed to consider how the UI could communicate that some filters in the query are disabled depending on which tab you are looking at. Alternatively, we considered re-arranging the hierarchy of the UI so that queries could only be created for one tab at a time.

Users had trouble mentally connecting the fields in the filters with the fields in the data table below (in the column headers). This led us to consider a number of solutions to mitigate this, like adding the ability to create a filter directly from the column, instead of choosing it from a list in the main query builder.
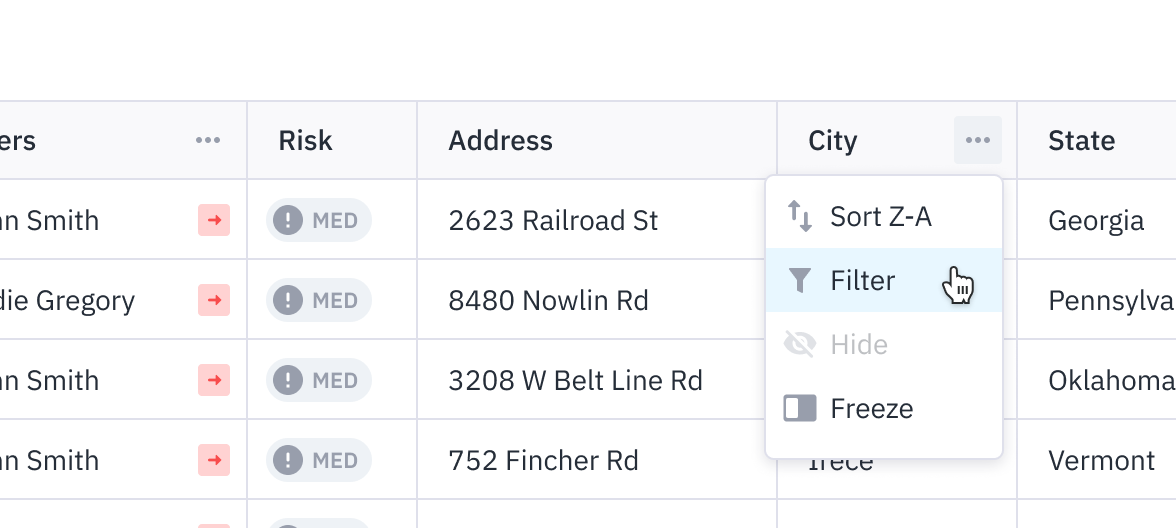
At Beam, we believe that we're never really done with a feature, launch day is only the beginning. Since we launched the re-designed data explorer we've been constantly gathering feedback from users and making incremental, iterative changes to the feature.